
大量のタスクを処理するようなシステムを組む場合、最近はサーバーレスが当たり前になってきたので、コンピューティング リソースが足りない場合は一時的に増やして処理しまうことができるようになってきました。
小さい簡単な処理をする場合は 最初から AWS Lambda などを使ったワークフローにシステムを構築しても良いのですが、外部システムとの連携などで再処理が必要だったりすると、サーバーレスだと緻密に組まれたピタゴラスイッチの様になってしまい融通が効かせにくいことがあります。
そこでキューイングを使うことで、システム間を一方方向のメッセージングを使った疎結合できます。
再処理する際もキューに同様のメッセージを積めば簡単に実現できるし、キューイングのシステム自体に再処理する仕組みも備わってることが多いです。
今回はキューイングを使ったシステムのデザインパターンの一種である、優先度付きキューイングを紹介します。
キューイングには AWS SQS や Rabbit MQ など いろいろなものがあり、キューイングのプロダクトによっては優先度付きのキューの機能を持ってるものもあります。
機能的なユースケースは以下の様なものが考えられます。
- 結果の同時書き込み数を制御したい場合
- 通常の処理とは別に優先させて処理する場合
- 余力のコンピューティングリソースで処理するようにしたい場合
例えば優先度付きキューの特徴を活かせるユーザーストーリーで例えると以下の様になります。
- 例えばGoogle Sheets の様な書き込み制限のある API に処理結果を書き込む
- 各地のIoT機器から不定期に時系列データが送られてきて、最新の情報をより優先して処理する
- 課金ユーザは優先して処理し、無課金ユーザーは余力で処理する
メッセージキューのプロダクト自体に優先度付き機能がない場合でも工夫すれば優先度付きキューを実現できます。
優先度付きキューの機能を持ってないプロダクトは以下のように、優先したいものとそれ以外が混ざってしまいます。

これを優先度付きにする仕組み自体はとてもシンプルで、2つのキューを用意し、それぞれのキューの役割は先に処理するキューそして、その後に処理するキューという感じの役割になります。
図で表現すると以下の様な感じになり、優先してさらに早く処理したい方のキューにコンシューマを多く割り当てます。
この方法だとコンシューマは1つのキューを知っておくだけなのでとてもシンプルな実装になります。
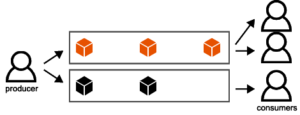
実装をさらに工夫して、1つのコンシューマが複数のキューを使い分けて処理する方法もあり、
実装が多少複雑になりますがコンピューティングリソースを効率的に使いまわせます。

この記事自体は優先度付きキューの説明だけですが、 優先付きキュー 自体は広く知られてるデザインパターンなのでググってみると具体的な実装コード等もあるので気になる方は更に深ぼってください。

